
Week 5. Grammar II: Syntax#
TL;DR [slides]
Syntax: putting words together
Grammatical vs. ungrammatical sentences
Words in linear order
Syntax beyond linearization
Syntax and language technology
Syntactic parsing: a classic task
But do we need syntax at all? Maybe not as much as before, but probably still yes
Putting words together#
Last week, we talked about words and their parts, morphemes: how morphemes are combined together, what kinds of morphemes exist and so on. Today, we move one level up and discuss how words can be put together to form phrases and sentences.
Important notion
Syntax studies how words combine into larger units like phrases and sentences.
This seems very similar to morphology – there are objects (morphemes) that combine together to make words; there are objects (words) that combine together to make sentences, kind of like this:

Aren’t syntax and morphology the same thing then, apart from working with different units? Why study them separately at all? That’s a fair consideration actually, which might be a reasonable concern for different languages to different extents, and boils down to the amount of distinct processes that work on the level of words but not at the level of sentences, and the other way around.
A tiny question along the way
We discussed an example of such process last week for Turkish: it works on the level of individual words but not above. Can you remember what it was?
Infinite sequences, finite means#
There is one interesting way where morphology and syntax seem to diverge from each other. When reading syntax introductions, one can often find the discussion of syntax as a tool to build infinite sequences from finite means. This means two things:
The number of sentences one can build in a language is potentially infinite;
The length of each individual sentence is also in principle unconstrained: if I had infinite time in my disposal, I could’ve given you an infinite sentence.
The first point can be illustrated by the fact that we constantly come up with sentences that have never been said before. Here is one: Lisa Bylinina will teach in Groningen this week – I am pretty sure it’s a brand new sentence, but it’s a part of English language, in a sense that you recognize that this is well-formed and you know what it means, so making and processing new sentences is clearly a core part of knowing and using language. With words, it does not really work this way – I can come up with a new word that nobody has seen before (here’s one: braplomindew), but it’s not very likely that people will understand me and, unless some time passes and more and more people use it the same way as I did, it will not really become a part of language.
What about word vs. sentence length? We saw one pretty long word last week:
How much longer can it get? With this particular one, it’s easy: we can repeat the prefix anti- potentially indefinitely with a meaningful result, even though after a while we might struggle to see what exactly it’s supposed to mean:
Similarly with sentences, in some cases we can infinitely repeat some parts of sentences and get potentially unbounded sentences:
But with sentences the sources of this potential infinity are more easy to come by and more diverse than that. As an example, a sentence can contain another sentence as its part, and once we see that grammar allows for this, it makes obvious the possibility of potentially infinite embedding, where a sentence contains a sentence, and it contains another sentence, and so on and so forth, infinitely (a property of a system known as recursion):
[S I called my friend [S' who knows my colleague ] ]
[S I called my friend [S' who knows my colleague [S'' who is away this semester ] ] ]
...
The thought here is this: it looks like there are some deep differences between combining morphemes into words and combining words into sentences. Sometimes these differences are not so clear, actually, but there’s something about this contrast in how free and creative word combinations are, while combinations of morphemes are less so. Syntax gives you combinatorial freedom that is somehow beyond the limits of combinatorial freedom of morphology.
If you are not totally convinced by this, think about dictionaries! Dictionaries are attempts to list all words, or maybe as many words as possible. We don’t really have dictionaries of sentences – and intuitively, it’s clear why. There are just too many, and it’s easier to make / analyze them on the fly, no need to list them. Similarly, think about things like longest word challenges, where people compete to come up with very long words that are longer than what other people came up with. If combinatorial power of word formation were as great as those for sentences, such challenges wouldn’t exist. But, to be fair, I looked it up now and there are longest sentence challenges, go figure.
Long story short, sentences are built from words, there is a potentially infinite set of sentences, and words can be treated as a finite set, as a bit of a simplification. So, syntax builds infinite sequences from finite means.
Words in the right order#
Let’s start by stating the maybe obvious fact that language has rules of combining words with each other, and not all word combinations in all orders result in phrases or sentences that the language allows. For instance, this sentence below is completely fine in English:
But arranging the very same words in different order might result in a sentence that sounds bad, or ill-formed, or what’s called ungrammatical – a speaker of English wouldn’t say this:
In the first sentence, the word order was Subject – Verb – Object (SVO), while in the second, ungrammatical, sentence the order is VSO, which is not allowed in English. But not all languages work like English in this respect. In Welsh, for example, VSO order is exactly how you put together a sentence:
| (1) | Prynodd | Elin | dorth | o | fara. |
| buy.PAST.3S | Elin | loaf | of | bread | |
| 'Elin bought a loaf of bread.' | |||||
In fact, the English word order is not even the most wide-spread word order among languages of the world, as far as we know. The most widespread group is SOV languages:

Some examples of SOV languages are Turkish, Japanese and Korean. Here’s an illustrating Japanese example:
| (2) | Watashi | wa | hon | o | yomimasu. |
| I | TOP | book | ACC | read | |
| 'I read the book' | |||||
Oversimplification alert!
According to this classification, languages like Dutch seem to fall in the SVO category. In simple sentences, it’s correct:
| Riny | vindt | linguistiek | leuk |
| subject | verb | object |
But when we are dealing with a complex sentence, the embedded one has SOV order:
| Thijs | vertelde | (aan) jou | dat | Riny | linguistiek | leuk | vindt |
| subject | verb | object | subject | object | verb |
Also, it’s not like the order is free or unfixed – it’s fixed, but in different ways in different constructions! This is the case for many languages in this classification. We will ignore this fact.
Languages constrain word order not only between the verb and its subject and/or object. Languages differ, for example, also in the following (this is not an exhaustive list!):
Whether language has prepositions or postpositions (that is, the linear placement of the adpositions) (see distribution across languages)
preposition |
postposition |
|
|---|---|---|
English |
with Anna |
*Anna with |
Turkish |
*ile Anna |
Anna ile |
The position of the possessor with the respect to the possessee (see distribution):
Poss-N |
N-Poss |
|
|---|---|---|
English |
Anna’s book |
*book Anna’s |
Irish |
*Anna leabhar |
leabhar Anna |
It’s interesting that these different word order parameters are not independent from each other. Linguists have been noticing interactions between them for quite a while now. Here are four relevant Greenberg Universals (we’ve seen one or two linguistic universals before!)
Universal 2: “In languages with prepositions, the genitive almost always follows the governing noun, while in languages with postpositions it almost always precedes.”
Universal 3: “Languages with dominant VSO order are always prepositional.”
Universal 4: “If a language has dominant SOV order and the genitive follows the governing noun, then the adjective likewise follows the noun.”
Universal 5: “With overwhelmingly greater than chance frequency, languages with normal SOV order are postpositional.”
Looking at these generalizations – let’s say, at the last one in particular – one might want to generalize these constraints in a way that makes them fall out of just one rule. For instance, we can say that a language is either head-final or head-initial:
if a verb combines with its object so that the object precedes the verb (as in the SOV order), the adposition combines with its noun so that the noun precedes the adposition (that’s like in Turkish);
and the other way around: if the verb precedes its object, then the adposition precedes its noun (that’s English).
That would give us two types of languages where two linear parameters are covered by just one rule:
Head-final languages (e.g. Turkish): O > V; N > ADP;
Head-initial languages (e.g. English): V > O; ADP > N.
But this attempt is complicated by the fact that not all languages fall nicely into one of these patterns, and also by the fact that we have to define what the head is in each of these cases.
A tiny question along the way
English does not conform to one of the generalizations above. Which one and how?
Some word order constraints received interesting potential explanations grounded in distributions of objects and their properties in the world, might be interesting as extra reading if you’re curious!
Culbertson, J., Schouwstra, M. and Kirby, S., 2020. From the world to word order: deriving biases in noun phrase order from statistical properties of the world. Language, 96(3), pp.696-717.
More complete recipes for simple sentences#
Constraints on word order work both ways:
They tell speakers where to put subject and object of the sentence with respect to the verb;
They tell the person hearing or reading the sentence which parts of the sentence are subjects and objects, based on their linear position.
What if a language does not have fixed word order? As a speaker, this means you can do whatever you want placing different parts of sentences with respect to each other (well, there are often still constraints, but let’s ignore that too). But as a listener, how do you know who did what to whom if the participants can appear anywhere in the sentence? Well, grammar governs things beyond just linear order.
Let’s look at ways you build a simple sentence in different languages in a way that takes into account things other than word order. We will need to start with a notion of semantic role.
Important notion
Semantic role, a.k.a. thematic relation, describes the type of involvement of a participant in an event described by the verb in the sentence.
We will look at just two:
Agent is a participant that initiates or causes the event, typically intentionally, and normally has control over the event.
Patient undergoes the action and changes its state, normally has no control over the course of the event.
In a sentence The dog attacked the cat, for example, the dog is the agent and the cat is the patient. There can be events with just one participant, and it can be an agent (Mary is walking) or a patient (John fell). Note that semantic roles (agent, patient) are not the same as grammatical roles (subject, object). Often, those coincide:

But sometimes, for example, in the passive construction, they do not: the agent can be the object, while the patient becomes the subject.

So, formulating a sentence requires mapping from its meaning-related components (such as participants and their type of participation) to syntax – and this mapping can sometimes be tricky. Let’s zoom in on this mapping for a bit and look at three types of events against the set of their main participants:
Events with two participants: an agent and a patient (typical ones are: kill, push, attack etc.);
Events with just one participant: an agent (run, exercise);
Events with just one participant: a patient (fall, die).
How does language encode them? Let’s look at English:
She attacked her.
She exercised.
She fell.
We see that the agent of the 2-participant event and the agent as well as the patient of the one-participant events have the same form (she), while the patient of the 2-participant event is grammatically different (her). Let’s unfold the system behind this fact step by step.

First, let’s map these pronouns to the roles the corresponding participants play in the event described by the sentence.
She in She exercised is an agent in a 1-participant event.
She in She fell is a patient in a 1-participant event.
She and her are the agent and the patient in the 2-participant event, respectively.
If we look at the forms of these pronouns again, we see that three of them coincide and one of them looks different – that’s the patient in the 2-participant event.
The two forms we are dealing with here – she and her – come from two different series of pronouns: 1) I, we, she, he, they vs. 2) me, us, her, him, them. These series differ in case: the first set is in nominative case, while the second set is in accusative. That’s what the observation is on a more abstract level: English, when it comes to pronouns, uses nominative case to encode the agent and the patient in 1-participant events and the agent of 2-participant events, and accusative for the patient of 2-participant events.
This way of mapping participants to their grammatical encoding (morphosyntactic alignment) is called accusative alignment (sometimes, nominal-accusative alignment).
NB: English distinguishes these cases only for pronouns, the full nouns would not show this contrast at least when we look at case marking, because English nouns don’t really have case!
Accusative alignment is very common but it’s not the only possible way!
Here is another very popular type of morphosyntactic alignment called ergative alignment (a.k.a. ergative-absolutive alignment): the agent of a 2-participant event is treated grammatically differently from other kinds of participants, as shown below for Warlpiri:
| (3) | ngarrka-ngku | ka | wawirri | panti-rni |
| man-ERG | AUX | cangaroo | spear-NPST | |
| 'The man is spearing the kangaroo.' | ||||
| (4) | kurdu | ka | wanka-mi | (5) | kurdu | kapi | wanti-mi | |
| child | AUX | speak-NPST | child | AUX | fall-NPST | |||
| 'The child is speaking.' | 'The child will fall.' | |||||||
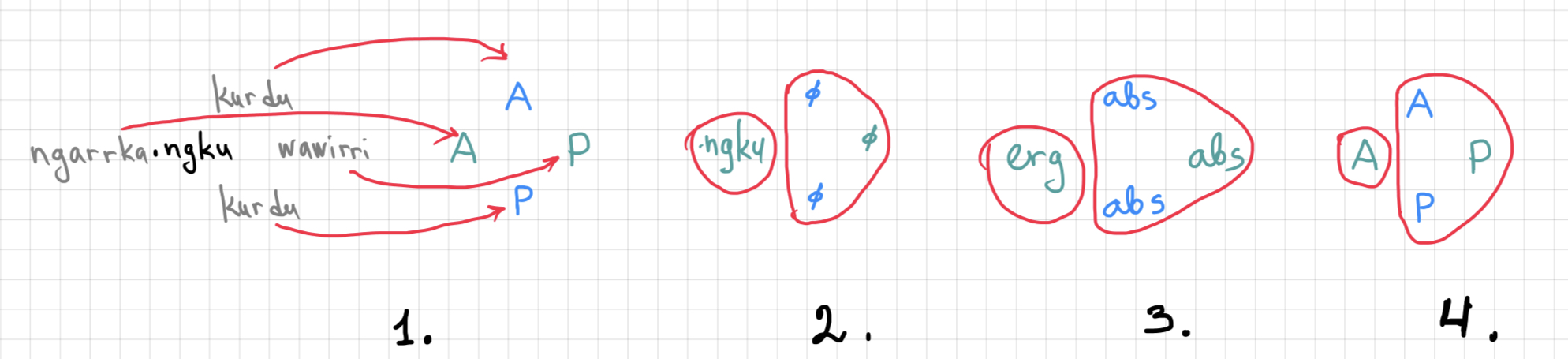
If we map nouns in these examples on the types of participants they encode –
We see that in the 1-participant situations, there is no case marking on the participants, as well as on the patient of the 2-participant event, but there is something – ngku – that marks the agent of the 2-participant event
This unmarked case is called absolutive case, and the ngku case here is an example of ergative case
We see that Warlpiri groups the nouns here in a different way than what English does with pronouns. This is ergative alignment.
Think about how English sentences with pronouns would look if English had ergative alignment. The 1-participant sentences would stay the same, but the 2-participant sentences could look something like *Them hit he, meaning They hit him.
Accusative and ergative alignment do not exhaust all attested possibilities. Here are just two more (remember I said above that English nouns do not use case to distinguish different types of participants – so, in this fragment of English language, the alignment is neutral):
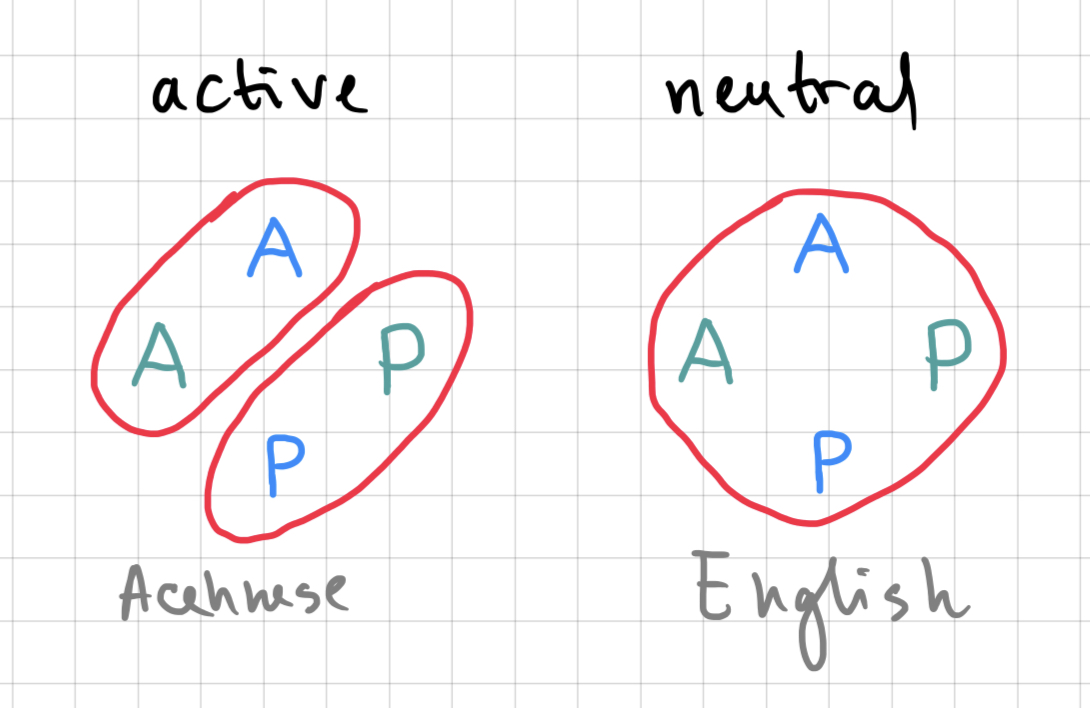
For the distribution of existing alignments, see the corresponding chapter of WALS. We don’t need to talk in any detail about all available alignments, but it’s important, I think, to wrap our heads around the fact that not all languages of the world organize their syntactic structures in the same ways as languages we are most familiar with. At the same time, there are limits to this variability, for instance, here is a sample of alignments that are not attested in natural language:
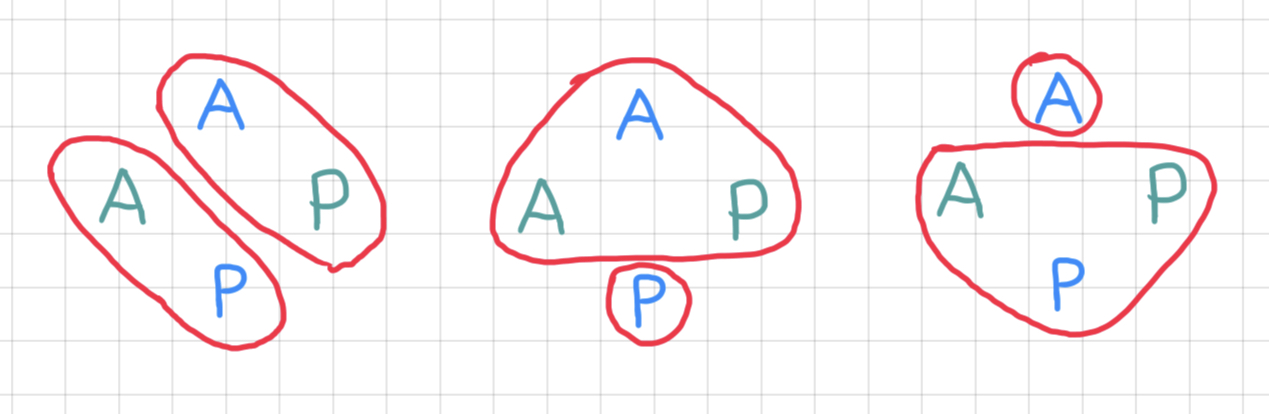
A tiny question along the way
What should a language look like to exemplify one of these alignments?
NB: Morphosyntactic alignment is not a classification of case marking – or, not exclusively. It’s a more general classification of the ways grammar encodes the basic clause structure. It can show itself as case, but it can also show as verbal agreement patterns, as in the examples from Halkomelem below, where the 3-person suffix on the verb only appears to agree with the agent of a 2-participant event and not in other situations:
| (6) | a. | ni | Ɂímǝš | b. | ni | q’wǝ´l-ǝt-ǝs | c. | ni | cǝn | q’wǝ´l-ǝt | |||
| AUX | walk | AUX | bake-TR-3ERG | AUX | I | bake-TR | |||||||
| 'He/she/it walks.' | 'He/she/it baked it.' | 'I baked it.' | |||||||||||
A tiny question along the way
What alignment does English show in its verbal agreement?
The take-away message from the discussion so far is this: combining words into sentences and phrases involves establishing grammatical connections between words and expressing these grammatical relations in one way or another. It can be word order and/or morphological marking of some type, such as case or agreement. Some ways of organizing these connections and expressing them are very common among languages, some less so, some are unattested for reasons we do or don’t have guesses about. Diving into this deeper can help you form expectations about language data and, consequently, can help you choose tools in how to deal with languages of different types.
Representing syntax#
I ended the previous subsection on a rather abstract note: words in a sentence are connected to each other in some way, and this connection can be expressed by grammar in different ways. But in order for us to be able to talk about these relations and connections, we should try to be more specific in how we represent them. There will be a much much more detailed discussion of this in the 2nd year of the program, during the ‘Computational Grammar’ course, but it might be helpful to say just one thing about it now.
There are two main ways to talk about syntactic relations, each with their own long-standing linguistic tradition. One of them is based on the idea of constituency, and the other one is based on dependency. They rely on two equally important and basic intuitions about what happens when two words combine together. On the one hand, these two words now form a bigger unit – a phrase, a constituent. On the other hand, there is now a directed relation between these two words, one of them depends on the other in some way. The very core of these two approaches can be shown on a simple sentence:
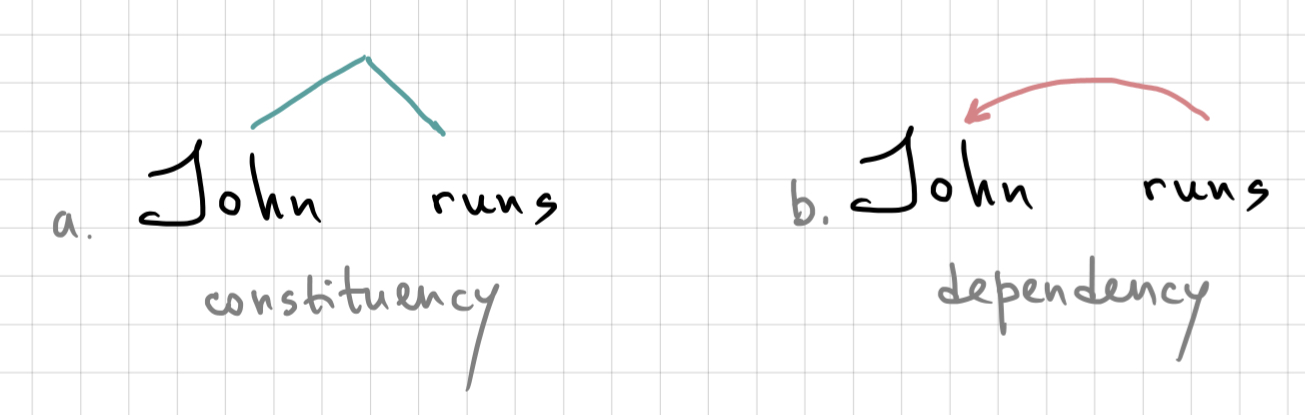
Constituency analysis emphasises the fact that these two words now function as a unit that can be used, for instance, as part of bigger phrases and sentences: Mary thinks that [John runs]. The dependency analysis shows the grammatical relation between the two words.
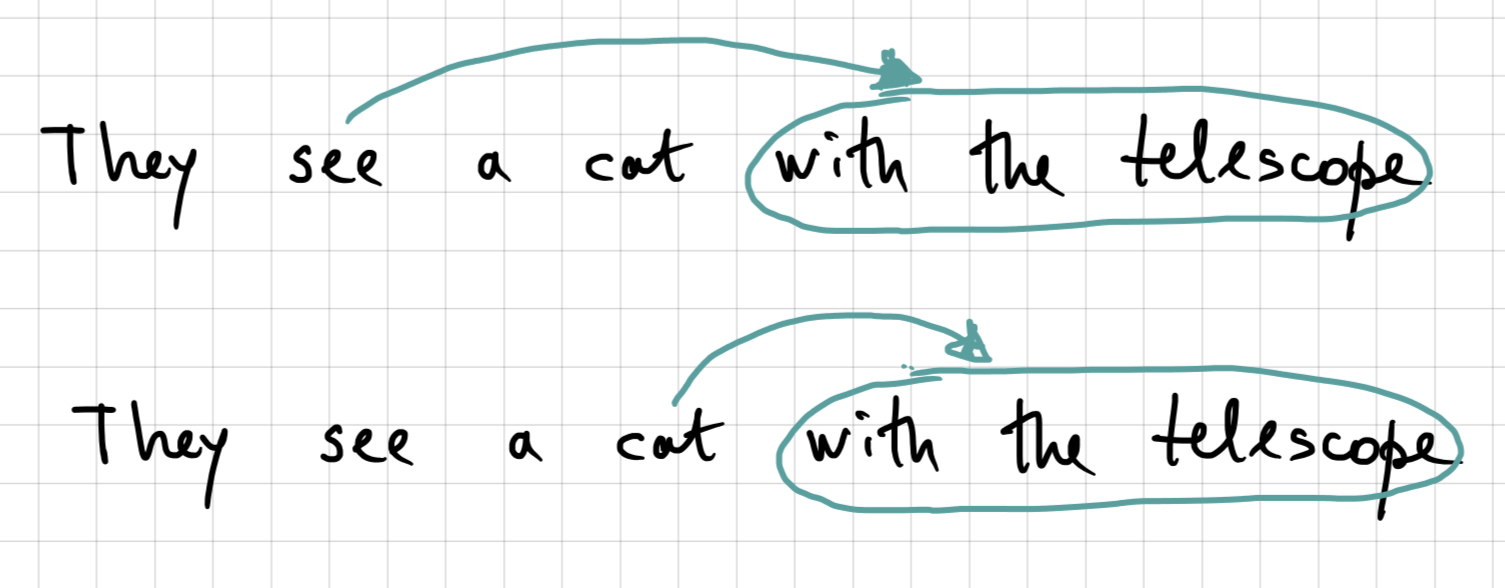
These two systems convey a lot of the same information. Recall a sentence from the very first lecture that I used to convince you that there is more to grammar than linear order of words:
This sentence is ambiguous – that is, has two readings. Both constituency analysis and dependency analysis can express the two structures that correspond to two readings of this sentence. In terms of dependencies, the with the telescope part bears a syntactic relation either to cat or to see, as I show in the partial dependency analysis below:
Constituents allow us to express the same intuition about how these two readings of the same sentence are different structurally, see the partial constituency analysis below:

In the first structure, with the telescope forms a constituent together with cat and to the exclusion of the verb. In the second structure, this is not the case: first, the constituent see a cat is formed, then it combines with the constituent with the telescope, so that the seeing-a-cat as a whole interacts with with the telescope.
Extra info
This sentence above is an example of attachment ambiguity – that is, where the phrase connects to the rest of the sentence. There are other types of syntactic ambiguity in language, here’s a short list with an example for each:
Modifier scope (which is actually also sort of attachment ambiguity): southern food store
Complement structure (which is actually also sort of attachment ambiguity): The tourists objected to the guide that they couldn’t hear
Coordination scope (which is, finally, something else, but also not a very nice thing to make a joke about; I wonder where I took this example from..): “I see,” said the blind man, as he picked up the hammer and saw.
Constituent structures and dependency structures are similar in many ways in the information they convey, but not equivalent. A transitive sentence can show these differences nicely:
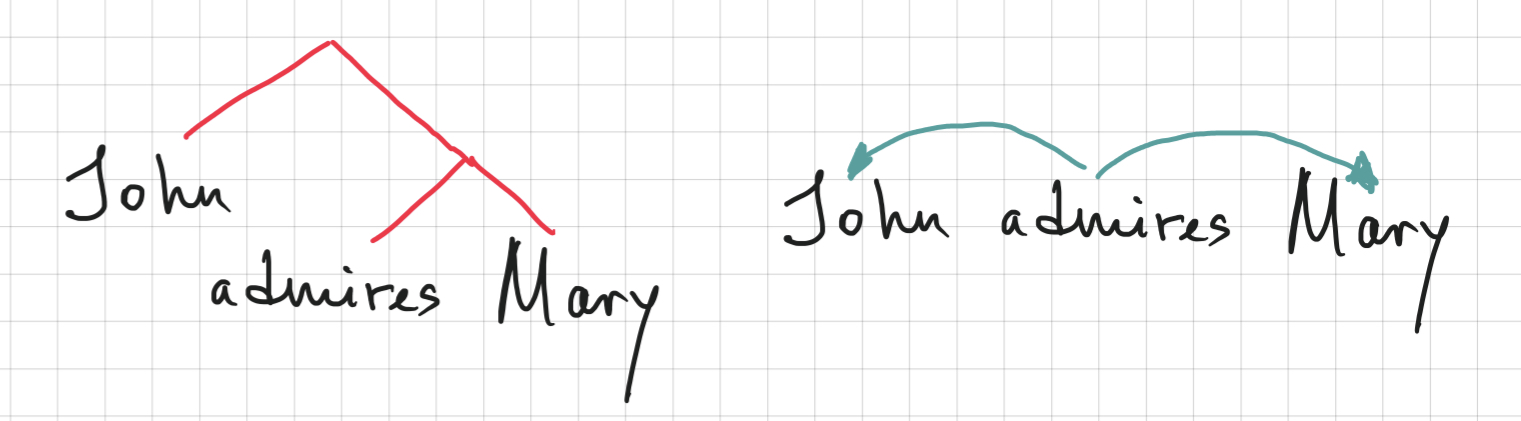
Here, both representations show that there is something going on between the word admires and the word Mary: they form a constituent, and there is a dependency relation that represents that connection too. The dependency relation is not symmetric though: the arrow starts at the verb and ends with the noun, not the other way around. If we were to recover this fragment of the dependency structure from the constituent structure, we wouldn’t know where to direct the arrow (unless we knew that one of the elements in the constituent is marked as head).
On the other hand, if we were to reconstruct the constituents from the dependency tree, we wouldn’t know what to group with what first: is it [[John admires] Mary] or [John [admires Mary]]? The arrows show that there are two connections, each between the verb and the noun – but it doesn’t encode the priority, that is, which connection is more tight or comes first. Maybe it doesn’t matter? It kind of does: there are reasons to think that the connection between the verb and the object is more tight and they form a constituent together to the exclusion of the subject. How do we know? We know because they behave as one unit:
They can be a conjunct in coordination: John hates Bill and admires Mary vs. *John admires and Ann dislikes Mary
They can undergo ellipsis together: John admires Mary and Bill does too (-> Bill admires Mary)
They participate in cleft constructions together: Admiring Mary is what John is good at vs. *John admiring is what Mary likes.
A lot more can be said about constituents and dependencies, but I leave this here now – just remember that these things exist! That should be enough as a starting point for syntax and its role in language technology.
Extra info
There are several very important topics in syntax that we were not able to cover. I don’t want to over-pack this class, but I invite you to look for information on these topics yourself. Some of them will be partially covered in the homework reading, some of them won’t:
Parts of speech!
Syntactic movement
Ellipsis
Pro-drop
Head marking vs. dependent-marking
Syntax and language technology#
Automatic syntactic analysis (known as syntactic parsing) is one of the classic NLP tasks: the text of the sentence serves as input, and the output is the syntactic structure, either as a constituency structure or a dependency structure. Let me show you both, using our previous example sentence:
sentence = "John admires Mary"
Let’s do the constituents first. I’ll be using Berkley Neural Parser (benepar), you can try out the no-coding demo yourself.
import benepar, spacy
from nltk import ParentedTree
from IPython.utils import io
with io.capture_output() as captured:
nlp = spacy.load('en_core_web_sm')
nlp.add_pipe("benepar", config={"model": "benepar_en3"})
sentence = list(nlp(sentence).sents)[0]
parse_tree = ParentedTree.fromstring('(' + sentence._.parse_string + ')')
parse_tree.pretty_print()
|
S
______|_____
| VP
| _____|___
NP | NP
| | |
NNP VBZ NNP
| | |
John admires Mary
The output is structurally the same as my hand-drawn tree in the previous section – but note the additional information that this tree contains, compared to my version: nodes in this tree have labels that I did not write. These labels mark categories of constituents in the nodes, where S, for example, is a simple declarative sentence and VP is a verb phrase (here, verb plus its object).
Let’s compare this to the dependency analysis from spaCy, a popular NLP library (see their no-coding demo if you want to try more examples):
spacy.displacy.render(sentence, style='dep')
Again, this is very similar to what I drew above! But this structure has more info – the dependency arrows now have labels that specify what type of relation we are looking at: a subject relation (nsubj) connecting the verb to its subject and a direct object relation (dobj) connecting the verb to the object.
Models performing syntactic parsers in these two different ways heavily rely on data resources that encode syntactic structures in these particular ways – syntactic treebanks.
An example of syntactic treebank annotated with constituency structure is Penn Treebank, with annotation format that looks like this:
(IP-MAT (NP-SBJ (PRO I))
(VBD saw)
(NP-OB1 (D the)
(N man)))
A very important resource for dependency structures is Universal Dependencies, which I discussed last week as a source of morphological information. Its syntactic annotation is the same as what we saw in the analysis by spaCy, and that’s not a coincidence:
# text = Kazna medijskom mogulu obnovila raspravu u Makedoniji
1 Kazna kazna NOUN Ncfsn Case=Nom|Gender=Fem|Number=Sing 4 nsubj _ _
2 medijskom medijski ADJ Agpmsdy Case=Dat|Definite=Def|Degree=Pos|Gender=Masc|Number=Sing 3 amod _ _
3 mogulu mogul NOUN Ncmsd Case=Dat|Gender=Masc|Number=Sing 1 nmod _ _
4 obnovila obnoviti VERB Vmp-sf Gender=Fem|Number=Sing|Tense=Past|VerbForm=Part|Voice=Act 0 root _ _
5 raspravu rasprava NOUN Ncfsa Case=Acc|Gender=Fem|Number=Sing 4 obj _ _
6 u u ADP Sl Case=Loc 7 case _ _
7 Makedoniji Makedonija PROPN Npfsl Case=Loc|Gender=Fem|Number=Sing 4 obl _ _
What do we need syntactic parsing for? I said it’s a classic NLP task, but I didn’t say anything about why it exists apart from the sole purpose of us admiring or hating the resulting parses.
The first – somewhat superficial – answer is that maybe we don’t need it much. During the last several years, there’s been a tendency to approach a lot of NLP tasks in an end-to-end fashion (if you remember this term from one of our previous lectures) rather than building pipelines of systems that produce different levels of linguistic analysis for the downstream task.
Moreover, some relatively recent models that were not trained for syntactic parsing at all end up learning something that resembles syntactic relations. A seminal paper that introduced the currently most successful deep learning architecture in NLP (Attention is all you need) has the following figures in the appendix, showing information flow between different words in a sentence (the technical details of what it means and how it works don’t matter now) with a note that these patterns look related to the structure of the sentence, which the model has never been shown explicitly during training. And it actually does look roughly like it – see prominent groups of words like [the law], [its applications] etc.
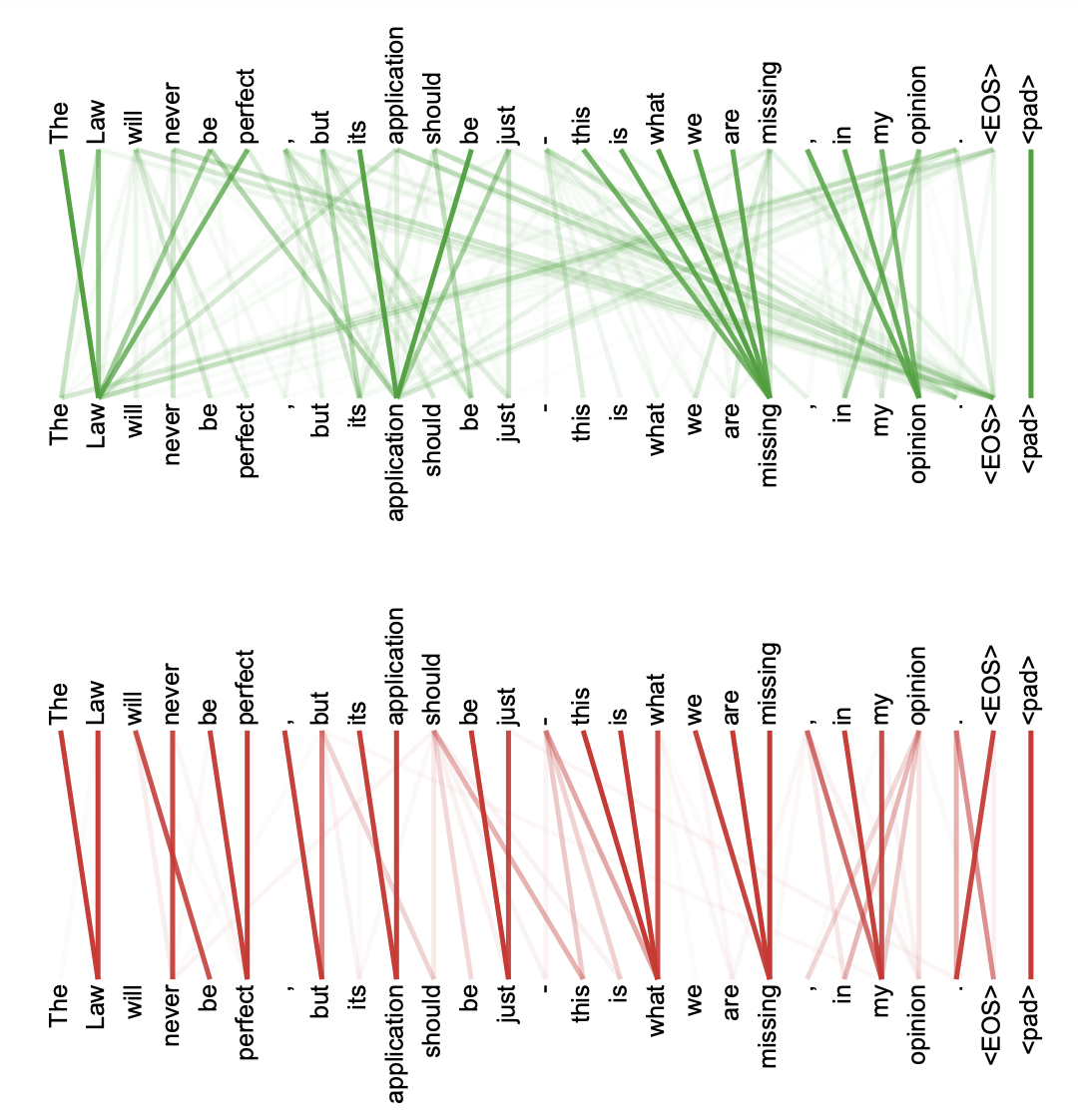
Further research analysing the inner workings of this type of models showed that, indeed, there is some syntax emerging in them without specialized training. Check this work out if you are curious:
Voita, L. et al. 2019. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. ACL.
Does this all mean that language technology practicioners do not need syntax or knowledge of syntax at all anymore? I think they probably still need it anyway.
First and foremost, you would be surprised how non-trivial the very idea of (un)grammaticality can be in the NLP world, and how this simple idea can change the course of an engineering approach to an NLP problem.
Second, as we saw with the structural ambiguity example above, syntactic structure is related to meaning, and therefore syntax is linked to natural language understanding – a huge research area and a very important super-task – in ways we will discuss more next week;
Identifying phrases and other units larger than words is still useful in a variety of downstream tasks, for instance in search – in cases when convenient search units are not individual words but something bigger, e.g. phrases.
Sometimes, depending on the task, a small handwritten grammar is a better way to go than a huge model. Such small handwritten grammars are often used to help virtual assistants recognize and act on commands that have simple predictable structure. Those grammars don’t always have to be true to the letter of linguistic syntactic theory, but it’s a grammar that breaks down a sequence of words into smaller units, so it is syntax in that sense. An example below shows a tiny grammar for the virtual assistant Alice that parses phrases like turn on the light in the bathroom, turn on air conditioning in the kitchen and the like, detecting what should be done and where, so that the structured request can be sent further down the pipeline:
root:
turn on $What $Where
slots:
what:
source: $What
where:
source: $Where
$What:
the light | air conditioning
$Where:
in the bathroom | in the kitchen | in the bedroom
Syntactic templates are very handy when it comes to generating a lot of synthetic data for whichever purpose you might need it. For example, to generate test data for the task of Natural Language Inference (given two sentences, does the second one follow from the first? we will discuss this task next week), you can put together a list of nouns (Mia, Lin etc.) and predicates (wore a mask etc.), as well as simple templates, and generate a bunch of sentences:
Premise:
[N1] and [N2] [Pred]
Hypothesis:
[N1] [Pred]
Premise: Mia and Lin wore a mask.
Hypothesis: Mia wore a mask.
Finally, I want to show one recent and, I think, very interesting use of syntactic parsing to improve performance of a very sophisticated model. Above I said that recent language models learn a little bit of syntax even when not trained for it. On the other hand, in the first lecture, I talked about cases where models actually do not learn syntax – or, at least, not enough of it. In particular, vision-and-language models have been shown to be pretty bad when it comes to semantically distinguishing sentences that encode different meanings by syntactic means:
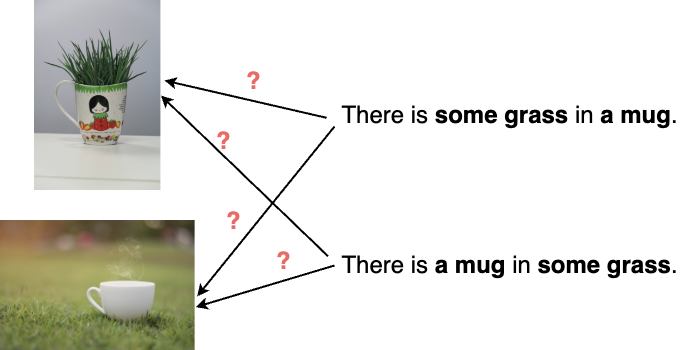
For text-to-image models, this can result in inaccuracies in the generated image when it comes to assigning the right properties to the right object, as discussed in this recent paper:
Rassin et al. 2023. Linguistic Binding in Diffusion Models: Enhancing Attribute Correspondence through Attention Map Alignment. To be presented at NeurIPS.
To help the model relate properties to objects more consistently, the authors first apply syntactic parsing to the text prompt, and then force the model to act on the detected connections during the image generation process (the details of how this is done exactly are way beyond what we need to discuss today):
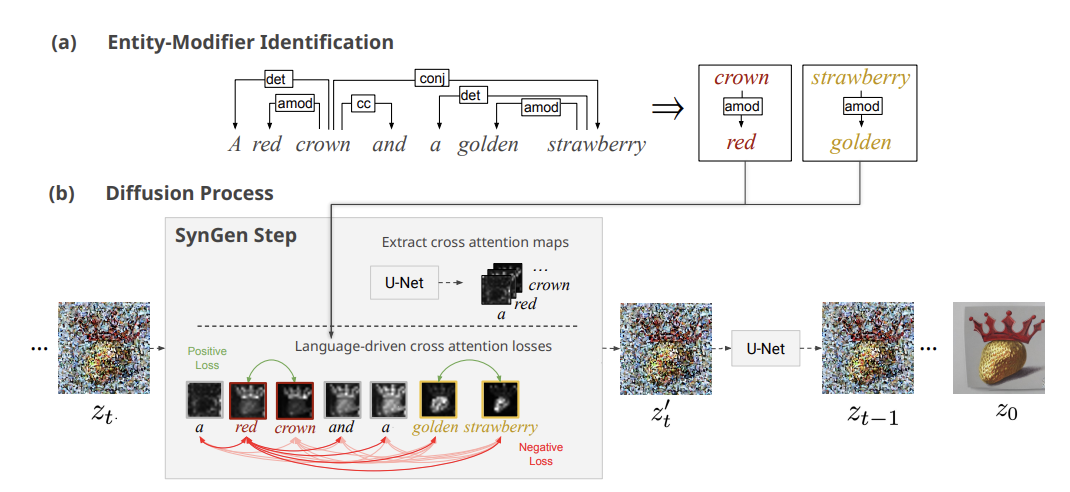
The result is more faithful to the meaning conveyed by the text prompt, as reflected in its syntactic structure, compare the outputs of the original model below and the syntactically guided one above:

I think that’s pretty cool! So, you never know.
Homework 5
Task 1
Read the following three bits from the textbook Bender, E.M. 2013. Linguistic Fundamentals for Natural Language Processing: 100 Essentials from Morphology and Syntax:
Chapter 5. Syntax: Introduction, pp. 53-55
Chapter 6. Parts of speech, pp. 57-60
Chapter 8. Argument types and grammatical functions, pp. 79-99
As usual, name (and say something about!) three things that the texbook discusses differently than I did or those missing from our class completely. Not from Chapter 6 though! We ignored parts of speech completely, unfortunately. But do read that part anyway.
Task 2
Imagine a language that’s almost like English, but a little bit different. Maybe a group of British travellers got stuck in a far-away island long, long ago, their language gradually changed and their descendents now speak this language. Here is a short text in that language, glossed:
| Chase-did | eagle-se | monkey | forest | in. | Escape-did | monkey | fast. | Fall-did | eagle. |
| chase-PST | eagle-CASE | monkey | forest | in | escape-PST | monkey | fast | fall-PST | eagle |
| 'An eagle chased a monkey in the forest. The monkey escaped fast. The eagle fell.' | |||||||||
Answer the following questions about this text:
Which order of subject, verb, object does the language have?
Does it obey all of Greenberg’s word order universals discussed above?
What type of morphosyntactic alignment does this language have when it comes to case marking?
What can we say about alignment when it comes to verb agreement?
Task 3
Run the first of the fake-English sentences in the text above (Chase-did eagle-se monkey forest in) through the syntactic parsers for English: the constituency parser and the dependency parser. Describe what you get: Did the parsers analyse the sentence in a similar way? If not, how do their analyses differ?